Unsupervised Learning is a fascinating branch of machine learning that uncovers hidden structures within unlabeled data. It allows algorithms to analyze data sets without predefined categories, making it a powerful tool for discovering insights that would otherwise remain hidden. From clustering customers based on purchasing behavior to identifying anomalies in financial transactions, this technique opens up new possibilities across various industries.
At its core, unsupervised learning functions by identifying patterns and relationships in data, contrasting sharply with supervised learning, where specific outcomes guide training. This approach is particularly useful for exploratory data analysis, revealing intrinsic groupings and trends that can inform decision-making. With various techniques ranging from clustering to dimensionality reduction, the potential applications are vast, making it a crucial area of study for data scientists and analysts alike.
Unsupervised Learning Fundamentals
Unsupervised learning is a type of machine learning where algorithms are used to analyze and cluster unlabelled data. Unlike supervised learning, where the model is trained on labeled input-output pairs, unsupervised learning algorithms draw inferences from datasets consisting of input data without labeled responses. This approach enables the algorithm to identify patterns, group similar data points, and uncover hidden structures within the data. The core principles of unsupervised learning revolve around exploring the data’s inherent traits, allowing the model to make sense of the complexities inherent in large datasets.
In unsupervised learning, the algorithm’s primary goal is to discover the underlying structure of the data. Techniques such as clustering and dimensionality reduction play a significant role in achieving this goal. Clustering involves grouping data points based on similarity, while dimensionality reduction techniques, like PCA (Principal Component Analysis), aim to simplify datasets by reducing the number of features while retaining essential information. These methods are widely used across various domains, including customer segmentation, anomaly detection, and recommendation systems.
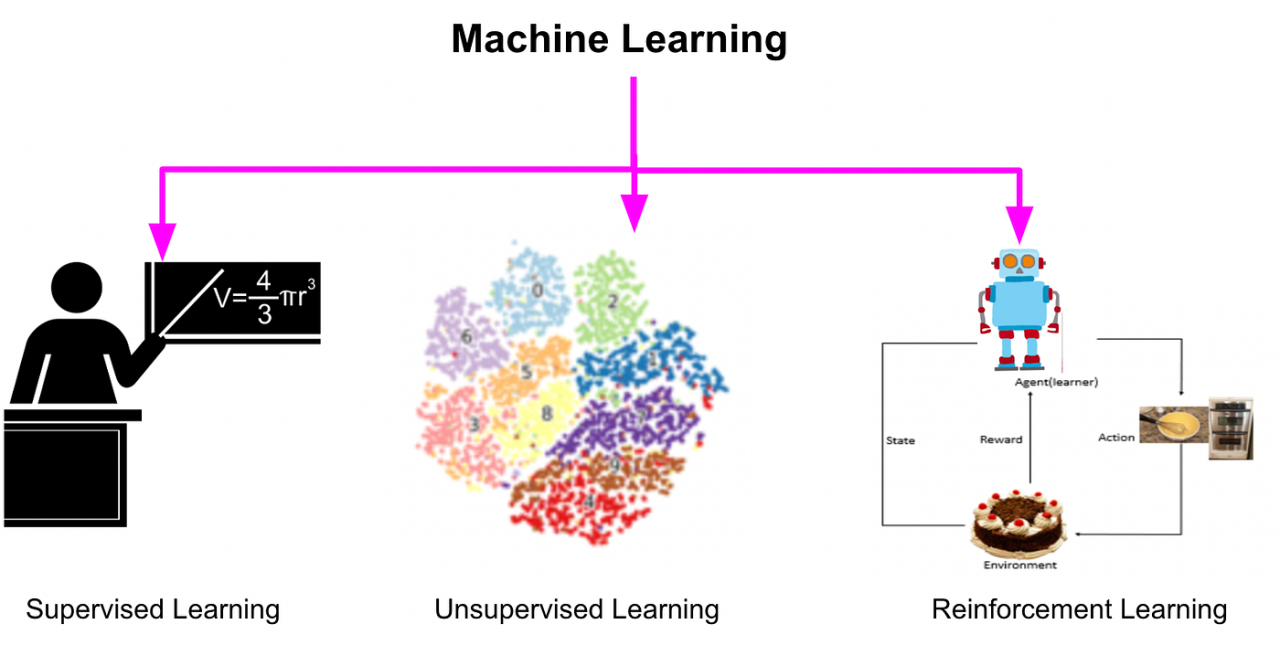
Differences Between Supervised and Unsupervised Learning
Understanding the distinctions between supervised and unsupervised learning is crucial for selecting the appropriate model for a given task. Supervised learning relies on labeled datasets, where each training example is paired with an output label. This allows the model to learn from examples and make predictions on new, unseen data. In contrast, unsupervised learning operates without labeled outputs, focusing instead on identifying patterns and groupings within the data.
– Data Dependency: Supervised learning requires a large amount of labeled data, which can be expensive and time-consuming to obtain. Unsupervised learning, however, can work with raw, unlabelled data, making it more flexible in situations where labeled data is scarce.
– Outcome Goals: The goal of supervised learning is to predict outcomes based on input features, while unsupervised learning seeks to explore data structures without any specific outcomes in mind.
– Model Evaluation: Supervised learning has clear metrics for evaluating performance, such as accuracy and precision, while unsupervised learning often requires subjective assessment or external validation methods to determine how well the model has identified patterns.
Problems Suited for Unsupervised Learning Techniques
Unsupervised learning techniques are particularly effective for a range of problems where discovering unknown patterns or structures is essential. The following scenarios exemplify situations where these techniques thrive:
– Clustering Analysis: This technique is vital in market segmentation, where businesses can group customers based on purchasing behavior, allowing for targeted marketing strategies.
– Anomaly Detection: Identifying unusual data points is crucial in fraud detection, network security, and fault detection, where deviations from patterns can signify potential issues.
– Dimensionality Reduction: In fields like image processing and genomics, dimensionality reduction techniques help visualize high-dimensional data, making it easier to analyze while retaining key information.
In each of these applications, unsupervised learning provides powerful insights that can guide decision-making and strategic planning across various industries.
Key Techniques in Unsupervised Learning

Unsupervised learning is a crucial area of machine learning where the model is trained using data that has not been labeled. This allows the model to identify patterns and structures without predefined categories. Two key techniques in this realm are clustering and dimensionality reduction, both essential for data exploration and analysis.
Clustering Techniques
Clustering is a powerful technique in unsupervised learning that groups similar data points into clusters. This method is fundamental for tasks such as customer segmentation, image recognition, and market research. Here are two popular algorithms in clustering:
- K-means Clustering: This algorithm partitions the dataset into K distinct clusters based on feature similarity. It starts by initializing K centroids and assigns each data point to the nearest centroid. The centroids are then recalculated based on the mean of the assigned points, iterating this process until convergence. An example application is in retail, where businesses can use K-means to segment customers based on purchasing behavior, identifying distinct groups for targeted marketing.
- Hierarchical Clustering: This technique builds a hierarchy of clusters either through a bottom-up (agglomerative) or top-down (divisive) approach. It is particularly useful for visualizing data relationships in a dendrogram format. For instance, in biology, hierarchical clustering is used to classify gene expression data, revealing evolutionary relationships among different species.
“Clustering helps uncover the inherent structure in data without requiring labels.”
Dimensionality Reduction Techniques
Dimensionality reduction is essential for simplifying complex datasets, making them easier to visualize and analyze. Two widely used techniques in this area are Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE).
- Principal Component Analysis (PCA): PCA reduces the dimensionality of data by transforming it into a new set of variables, the principal components, which capture the majority of the variance in the data. This technique is often applied in image processing, where it can reduce the number of features in a dataset without significant loss of information, streamlining the computational process for further analysis.
- t-SNE: t-SNE is particularly effective for visualizing high-dimensional data by reducing it to two or three dimensions. It works by converting the similarities between data points into joint probabilities and then optimizing these probabilities to create a low-dimensional representation. An example of its application is in the visualization of complex neural network outputs, allowing researchers to observe clusters of similar data points effectively.
Association Rule Learning
Association rule learning focuses on discovering interesting relations between variables in large datasets, often used in market basket analysis. This technique identifies patterns, such as products frequently purchased together, providing insights for cross-selling and upselling strategies.
- For instance, a grocery store may find that customers who buy bread often buy butter as well. By applying the Apriori algorithm, the store can create rules that inform product placements and promotions, enhancing sales opportunities.
- Another real-world application lies in recommendation systems, where association rules can help suggest products based on user behavior, significantly improving user experience and engagement.
“Association rule learning reveals hidden patterns that can drive strategic business decisions.”
Applications of Unsupervised Learning
Unsupervised learning serves a vital role in various domains, offering innovative solutions to complex problems without the need for labeled data. Its ability to discern patterns, group similar data points, and identify anomalies facilitates a wide array of practical applications. In this segment, we will explore the significant applications of unsupervised learning in customer segmentation for marketing strategies, anomaly detection across industries, and enhancements in natural language processing.
Customer Segmentation for Marketing Strategies
Customer segmentation is a fundamental marketing strategy that involves dividing a customer base into distinct groups based on shared characteristics. Unsupervised learning algorithms, such as K-means clustering and hierarchical clustering, are pivotal in identifying these segments without prior labeling. This approach enables marketers to tailor their strategies by understanding customer preferences, behaviors, and purchasing patterns.
Innovative applications include:
- Market Basket Analysis: By analyzing purchasing patterns, businesses can identify which products are frequently bought together, allowing for targeted promotions.
- Behavioral Segmentation: This involves categorizing customers based on their online behavior, such as browsing history and interaction frequency, to create personalized marketing campaigns.
- Demographic Segmentation: Unsupervised algorithms group customers based on demographics (age, income, location), enabling more focused advertising efforts.
These strategies help in improving customer engagement and increasing sales by providing relevant offerings to specific segments.
Anomaly Detection in Various Industries
Anomaly detection is a critical application of unsupervised learning, aimed at identifying unusual patterns or outliers in data that may indicate fraud, errors, or rare events. Various industries leverage this capability to enhance security, improve operational efficiency, and mitigate risks.
Key applications encompass:
- Finance: In the financial sector, unsupervised learning models detect fraudulent transactions by identifying behavior that deviates from established patterns, significantly reducing loss.
- Healthcare: Anomaly detection algorithms help monitor patient health data, identifying unusual patterns that may suggest medical complications, thus enabling timely interventions.
- Manufacturing: By analyzing sensor data from machinery, unsupervised learning can identify faults or irregularities, allowing for predictive maintenance and reducing downtime.
The utilization of these methods enhances decision-making and operational efficiency across these sectors.
Applications in Natural Language Processing
In the realm of natural language processing (NLP), unsupervised learning enhances various tasks by enabling models to learn from unstructured text data. This capability is crucial for applications that require understanding and generating human language.
Significant tasks improved by unsupervised learning include:
- Topic Modeling: Algorithms like Latent Dirichlet Allocation (LDA) help in discovering abstract topics within a collection of documents, facilitating better organization of information.
- Word Embeddings: Techniques such as Word2Vec utilize unsupervised learning to capture the semantic meaning of words based on their context, thus improving tasks like sentiment analysis.
- Text Summarization: Unsupervised methods can automatically summarize long texts by identifying key phrases and ideas, thereby streamlining information processing.
These applications showcase how unsupervised learning contributes to advancing technology in understanding and generating human language more effectively.
Challenges in Implementing Unsupervised Learning
Implementing unsupervised learning models presents various challenges that can significantly impact their effectiveness and usability. Despite the potential benefits of extracting meaningful patterns from unlabeled data, practitioners often encounter hurdles that can hinder model performance and interpretability.
Common Challenges Faced in Unsupervised Learning
Unsupervised learning deals with data that lacks explicit labels, making it challenging to evaluate the performance of models. Some of the common challenges include:
- Model Selection: Choosing the right algorithm or model can be difficult due to the absence of labeled data. Different models may capture different aspects of the data, leading to varied interpretations.
- Evaluation Metrics: Without ground truth labels, it becomes challenging to measure the accuracy or performance of the models. This often leads to reliance on subjective measures or domain-specific criteria.
- Scalability: Unsupervised learning methods may struggle with large datasets, especially those that require significant computational resources, like clustering algorithms that need to compute distances among data points.
- Interpretability: The results of unsupervised learning can be difficult to interpret, as the relationships and structures identified may not always be straightforward or intuitive to understand.
Issues Related to Data Quality and Preprocessing
Data quality plays a crucial role in the success of unsupervised learning algorithms. Poor quality data can lead to misleading conclusions and ineffective models. Key issues include:
- Noisy Data: Irrelevant features or outliers can distort the learning process, causing models to capture noise rather than meaningful patterns.
- Missing Values: Incomplete datasets can lead to biased results or inefficiencies in model training. Proper imputation or handling of missing data is essential before analysis.
- Feature Scaling: Features with different scales can adversely affect distance-based algorithms (like K-means), leading to suboptimal clustering results.
- Dimensionality Reduction: High-dimensional spaces can complicate pattern detection. Techniques like PCA (Principal Component Analysis) can help, but they also require careful consideration of variance retention.
Impact of Overfitting and Underfitting in Unsupervised Learning
In unsupervised learning, overfitting and underfitting are common issues that can compromise the model’s ability to generalize to unseen data. Understanding their implications is vital for successful implementation.
- Overfitting: This occurs when a model learns noise and outliers in the training data, resulting in poor generalization. For instance, a clustering algorithm may create overly complex clusters that do not reflect the true data distribution. To mitigate this, techniques such as cross-validation or regularization can be beneficial.
- Underfitting: Conversely, underfitting happens when the model is too simple to capture the underlying structure of the data. An example is using a linear model for inherently nonlinear data. Employing more complex models or incorporating additional features can help address underfitting.
Evaluating Unsupervised Learning Models
In the realm of unsupervised learning, assessing the effectiveness of models is crucial, especially given the absence of labeled data. The evaluation process not only helps in understanding how well a model has performed, but it also guides future improvements. This discussion centers on a framework for evaluating unsupervised learning models, emphasizing the relevance of metrics like the silhouette score and the Davies-Bouldin index.
Evaluation Metrics for Unsupervised Learning
Choosing the right evaluation metrics is essential for determining the quality of the clusters formed by unsupervised learning algorithms. Two widely used metrics are the silhouette score and the Davies-Bouldin index.
The silhouette score measures how similar an object is to its own cluster compared to other clusters, with a range of -1 to 1. A higher silhouette score indicates better-defined clusters.
Silhouette Score = (b – a) / max(a, b)
Where:
– a is the average distance between a sample and all other points in the same cluster.
– b is the average distance between a sample and all points in the next nearest cluster.
The Davies-Bouldin index, on the other hand, evaluates the average similarity ratio of each cluster with the cluster that is most similar to it. A lower index value signifies better clustering.
Davies-Bouldin Index = (1/n) * Σ max(j≠i) (Si + Sj) / d(i, j)
Where:
– Si is the average distance of all points in cluster i to the centroid of cluster i.
– d(i, j) is the distance between the centroids of clusters i and j.
Visualizing the results of unsupervised learning is equally important. Visualization helps in intuitively assessing model performance and the distribution of data points across clusters.
Importance of Visualization in Model Evaluation
Visualizing unsupervised learning results provides insights that numerical metrics alone might not convey. Techniques such as t-SNE (t-distributed Stochastic Neighbor Embedding) and PCA (Principal Component Analysis) can reduce the dimensionality of high-dimensional data, making it possible to visually inspect cluster formations.
For instance, a 2D plot generated from t-SNE can reveal not only how distinct the clusters are but also highlight any potential overlaps or misclassifications. This process aids in identifying the underlying structure of the data, which may lead to important discoveries that influence model adjustments.
Case Studies in Evaluating Unsupervised Learning Results
Several case studies illustrate the methodologies used to evaluate unsupervised learning results effectively. One notable example is the application of clustering in customer segmentation, where businesses aim to understand their customer base better.
In a study conducted by a retail company, K-means clustering was used to segment customers based on purchasing behavior. The silhouette score indicated well-defined clusters, while the Davies-Bouldin index confirmed that the clusters were adequately distinct. Subsequently, the results were visualized using a scatter plot, facilitating an easy interpretation of customer segments, which led to targeted marketing strategies.
Another case involved the exploration of gene expression data using hierarchical clustering. Researchers utilized the Davies-Bouldin index to evaluate the quality of clusters formed based on gene similarities. Through visualization in heat maps, they were able to discern patterns associated with specific diseases, which proved pivotal for further research and understanding of those conditions.
These case studies highlight that rigorous evaluation practices, supported by appropriate metrics and visual outputs, are essential for deriving meaningful insights from unsupervised learning models.
Future Trends in Unsupervised Learning
The landscape of unsupervised learning is rapidly evolving, particularly with the advancements in deep learning technologies. These innovations are driving the development of more sophisticated algorithms that can extract meaningful patterns from unlabelled data. As industries increasingly rely on data-driven decision-making, the potential applications of unsupervised learning expand, paving the way for a significant impact across various sectors.
The integration of unsupervised learning into artificial intelligence (AI) and machine learning (ML) applications is anticipated to enhance their capabilities. This approach allows for the analysis of vast amounts of data without the need for explicit labels, enabling organizations to uncover insights that were previously hidden. The following points highlight some emerging trends and implications for future applications.
Advancements in Deep Learning Technologies
Deep learning continues to revolutionize the way unsupervised learning is implemented. Recent advancements include the development of more complex neural network architectures and algorithms that improve the accuracy and efficiency of data processing. Key advancements include:
- Variational Autoencoders (VAEs): These models enable the generation of new data points similar to the training set while capturing complex distributions.
- Generative Adversarial Networks (GANs): GANs have become popular for creating realistic synthetic data, which can be useful in training other models without the need for extensive labeled datasets.
- Self-Supervised Learning: This technique leverages the inherent structure of data to create pretext tasks that allow models to learn useful features without human intervention.
Potential Applications Across Various Sectors
The versatility of unsupervised learning opens up numerous applications across different sectors. For instance, in healthcare, unsupervised learning can help identify patient segments for personalized treatment plans. In finance, it plays a role in anomaly detection for fraud prevention. The following sectors are expected to benefit significantly:
- Retail: Analyzing consumer behavior patterns to optimize inventory management and personalize marketing strategies.
- Manufacturing: Predictive maintenance through unsupervised anomaly detection, minimizing downtime and costs.
- Transportation: Enhancing route optimization and demand forecasting based on historical travel data.
Predictions for the Evolution of Unsupervised Learning
As the capabilities of unsupervised learning grow, several predictions can be made about its future trajectory and implications for research and industry practices. These include:
- Increased Collaboration with Supervised Learning: Hybrid models combining unsupervised and supervised learning techniques will likely become more common, improving overall performance and accuracy.
- Greater Focus on Ethical AI: As unsupervised learning becomes more prevalent, the emphasis on ethical considerations, such as bias detection in algorithms, will also increase.
- Expanding Interpretability: The development of methods to interpret and visualize the results of unsupervised learning will enhance trust and understanding among users and stakeholders.
The future of unsupervised learning will largely depend on our ability to harness its potential responsibly and effectively, ensuring that it complements existing methodologies while driving innovation across sectors.
Last Recap
In summary, unsupervised learning is not just a technical concept but a gateway to understanding complex data in meaningful ways. As it continues to evolve alongside advancements in artificial intelligence, the implications for industries such as marketing, finance, and healthcare are immense. Embracing these techniques can lead to innovative strategies and improved outcomes, underscoring the importance of continuing exploration in this dynamic field.
Questions Often Asked
What is the main difference between supervised and unsupervised learning?
Supervised learning uses labeled data to train models, while unsupervised learning deals with unlabeled data to find hidden patterns.
Can unsupervised learning be used for predictive analytics?
While unsupervised learning itself is not predictive, it can be used to inform predictive models by uncovering patterns that are then used in supervised learning.
What are some common algorithms used in unsupervised learning?
Common algorithms include K-means clustering, hierarchical clustering, Principal Component Analysis (PCA), and t-distributed Stochastic Neighbor Embedding (t-SNE).
Is unsupervised learning suitable for all types of data?
No, unsupervised learning performs best with large datasets where patterns can emerge; it may struggle with small or overly noisy datasets.
How can I evaluate the performance of an unsupervised learning model?
Performance can be evaluated using metrics like the silhouette score or Davies-Bouldin index, and by visualizing clustering results.