Neural Networks are revolutionizing the way we approach complex problems in technology and science. By mimicking the human brain’s interconnected network of neurons, these systems enable machines to recognize patterns, make predictions, and learn from data in a remarkably efficient manner. As we delve into this intriguing domain, we will explore the essential components and architectures that define neural networks, the crucial role of training data, and the exciting applications that are shaping various industries today.
The magic of Neural Networks lies not only in their theoretical foundations but also in their practical implementations. From improving healthcare diagnostics to powering autonomous vehicles, the applications are vast and continually evolving, making it imperative to understand how these systems function and what challenges they face. Join us as we navigate through the intricacies of Neural Networks, shedding light on their architecture, training processes, and the future trends that may redefine their capabilities.
Understanding the Fundamentals of Neural Networks
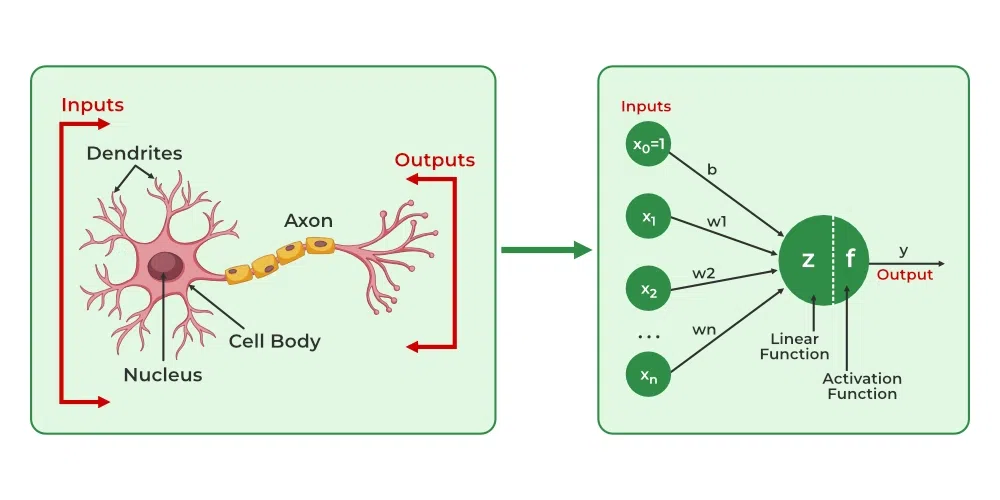
Neural networks have revolutionized the field of artificial intelligence, enabling machines to learn and make decisions in a manner reminiscent of the human brain. At their core, neural networks consist of interconnected nodes, or neurons, organized into layers. This structure allows them to process complex data and learn from it through a method called deep learning. Understanding the components and workings of neural networks is crucial for grasping how they operate and their impact on various applications.
The primary components of a neural network include neurons, layers, and connections between these neurons. A neuron receives input from multiple sources, processes it, and produces an output that is passed on to other neurons. These neurons are typically arranged in layers: an input layer, one or more hidden layers, and an output layer. The input layer receives the initial data, while the hidden layers perform various transformations on this data. The output layer generates the final results or predictions based on the processed information. Each connection between neurons has an associated weight, which determines the strength of the signal being passed along. The adjustment of these weights is how neural networks learn.
Activation Functions
Activation functions play a crucial role in introducing non-linearity into the neural network. They determine if a neuron should be activated, or in other words, if it should contribute to the output based on the weighted sum of its inputs. The significance of activation functions lies in their ability to help neural networks learn complex patterns in data. Without non-linear activation functions, a network would essentially behave like a linear model, limiting its power and effectiveness.
Common activation functions include the Sigmoid, Tanh, and ReLU (Rectified Linear Unit). The Sigmoid function squashes input values to a range between 0 and 1, making it useful for binary classification tasks. The Tanh function is similar but outputs values between -1 and 1, which can help in reducing issues related to zero-centered data. ReLU, on the other hand, allows for faster training and is widely used in deep networks due to its efficiency in handling gradients.
Types of Neural Networks and Their Applications
Various types of neural networks have been developed, each tailored for specific tasks and applications. For instance, Convolutional Neural Networks (CNNs) are predominantly used in image recognition and processing tasks. They excel at detecting patterns and spatial hierarchies in visual data. A notable application is in facial recognition technologies, which are employed in security and social media platforms.
Recurrent Neural Networks (RNNs) are designed to work with sequential data, making them ideal for language processing tasks. RNNs have been effectively used in applications such as language translation and speech recognition, where context and order of input data are essential.
Additionally, Generative Adversarial Networks (GANs) represent a groundbreaking approach in the field of artificial intelligence. They consist of two networks—the generator and the discriminator—that compete against each other. GANs have been used to create realistic images, videos, and even generate art, showcasing their potential for creativity and innovation in digital content generation.
Overall, the understanding of neural networks, their fundamentals, activation functions, and various types is essential to leveraging this technology in solving real-world problems.
The Architecture of Neural Networks and Its Variations
Neural networks have evolved into diverse architectures, each serving unique purposes and optimally handling specific types of data. Understanding these architectures is pivotal for selecting the right model depending on the task at hand, whether it be image recognition, natural language processing, or time series forecasting.
Neural network architectures can be categorized into three primary types: feedforward neural networks, convolutional neural networks, and recurrent neural networks. Each architecture has its own strengths and weaknesses, influencing performance based on the nature of the input data and the intended application.
Feedforward Neural Networks
Feedforward neural networks are among the simplest types of neural networks, primarily characterized by the unidirectional flow of information from input to output layers without cycles. This architecture consists of an input layer, one or more hidden layers, and an output layer.
The advantages of feedforward neural networks are their straightforward implementation and efficiency. They perform well in tasks like basic classification problems and regression. However, they struggle with sequential data or temporal dependencies since they lack memory elements.
Convolutional Neural Networks
Convolutional neural networks (CNNs) are designed to process data with a grid-like topology, making them particularly effective for image-related tasks. They utilize convolutional layers that apply filters to input images, enabling the network to learn spatial hierarchies of features.
The strengths of CNNs lie in their ability to automatically detect and learn features without manual feature extraction, significantly reducing the need for preprocessing. CNNs excel in tasks like image classification, object detection, and image segmentation. On the downside, they require substantial computational resources and large labeled datasets for training, which might be a limitation in some scenarios.
Recurrent Neural Networks
Recurrent neural networks (RNNs) are specifically designed to handle sequential data, making them suitable for applications like natural language processing and time-series analysis. RNNs have loops allowing information to be retained from previous inputs, enabling the model to maintain a memory of previous computations.
The primary strength of RNNs is their capability to model dependencies in sequential data, which is critical for understanding context in language and time-series trends. However, traditional RNNs can suffer from issues like vanishing and exploding gradients, which limit their effectiveness in learning long-range dependencies. Variants like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) address these limitations, making RNNs more robust.
The choice of architecture directly impacts the neural network’s performance on specific tasks. For example, while a feedforward network might suffice for a simple classification task, a CNN would dramatically outperform it for image-related tasks, and RNNs would be necessary for any scenario requiring the understanding of sequences. Hence, selecting the appropriate architecture is crucial in achieving optimal results for varied applications.
The Role of Training Data in Neural Network Performance

The performance of a neural network significantly hinges on the quality and quantity of the training data it is provided. High-quality data not only enhances the model’s ability to learn patterns but also minimizes overfitting and underfitting issues. The importance of robust training data cannot be overstated, as it essentially dictates how well a neural network will generalize its learning to unseen data.
The quality of the training data is vital for the development of effective neural networks. If the training data is noisy, biased, or unrepresentative of the problem domain, the resulting model will likely perform poorly in real-world applications. Conversely, a diverse and comprehensive dataset allows the model to capture the underlying trends and relationships in the data more effectively. Additionally, the quantity of training data also plays a critical role. More data typically helps in creating more generalized models, allowing neural networks to learn from a broader range of examples, which in turn enhances their predictive capabilities.
Data Preprocessing Techniques
Before training a neural network, data preprocessing is essential to ensure that the data is in an optimal state for learning. Below are some common preprocessing techniques that can help improve the quality of training data:
- Normalization: This technique adjusts the range of data values to a common scale without distorting differences in the ranges of values. It often involves scaling input features to a range between 0 and 1 or standardizing them to have a mean of zero and a standard deviation of one.
- Data Cleaning: This involves identifying and correcting errors or inconsistencies in the dataset. Removing duplicates, addressing missing values, and correcting mislabelled data are crucial steps to ensure high data quality.
- Feature Engineering: This process involves creating new features or modifying existing ones to improve model performance. It can include techniques such as polynomial features, interaction terms, or encoding categorical variables.
- Data Augmentation: Particularly in image processing, this technique artificially increases the size of the training dataset by creating modified versions of existing data. Techniques such as rotation, flipping, and zooming help improve model robustness.
Evaluating the performance of a neural network based on the training data used is crucial to ensure its effectiveness. Several methods can be employed to assess performance:
1. Train-Test Split: Separating the dataset into a training set and a test set allows for the evaluation of model performance on unseen data. A common split ratio is 80/20 or 70/30, which helps detect overfitting.
2. Cross-Validation: This technique involves dividing the training data into multiple subsets and training the model multiple times, each time using a different subset for validation. k-fold cross-validation is a popular method that provides a more reliable estimate of model performance.
3. Performance Metrics: Using metrics such as accuracy, precision, recall, F1-score, and area under the ROC curve (AUC-ROC) offers a quantitative way to evaluate how well the neural network performs on various aspects of the data.
4. Learning Curves: Plotting training and validation loss over epochs helps visualize how the model is learning. It can indicate whether the model is overfitting, underfitting, or learning appropriately.
In conclusion, the effective training of neural networks is significantly influenced by the quality and amount of training data. Employing appropriate data preprocessing techniques and evaluating performance through systematic methods ensures the development of robust models capable of performing well in real-world scenarios.
Deep Learning and Its Connection to Neural Networks
Deep learning has emerged as a revolutionary approach within the field of artificial intelligence and machine learning, primarily due to its ability to process large volumes of data and extract meaningful patterns. At its core, deep learning leverages neural networks, which are computational models inspired by the human brain. These models consist of interconnected layers that enable them to learn from vast amounts of data, making them particularly effective for tasks such as image recognition, natural language processing, and autonomous systems.
Deep learning refers to a subset of machine learning that employs algorithms called neural networks, which are defined by multiple layers of neurons. Each layer in a neural network extracts different features from the data, allowing for a hierarchical representation of information. The significance of depth in deep learning models cannot be overstated. As the number of layers increases, the model’s capacity to learn complex patterns improves. This is because deeper networks can capture intricate relationships within the data that shallow networks may overlook. For instance, in image recognition, initial layers may detect edges and basic shapes, while deeper layers can identify more complex structures like faces or objects.
The distinction between traditional machine learning and deep learning approaches lies primarily in their methodologies and requirements. Traditional machine learning models often rely on feature extraction, where the engineer manually selects the features deemed important for the model. This process can be time-consuming and requires domain expertise. In contrast, deep learning automates this feature extraction process. With sufficient training data, deep networks learn to identify relevant features on their own.
“Deep learning models excel in environments with high-dimensional data, extracting features without explicit programming.”
The increased capacity of deep learning models leads to remarkable performance improvements in various applications. For instance, Google’s AlphaGo utilized deep learning to defeat a world champion in the game of Go, showcasing the potential of these models in complex, strategic tasks. The integration of deep learning with neural networks represents a significant advancement in computational capabilities and has the potential to reshape various industries through automation and predictive analytics.
Challenges in Training Neural Networks
Training neural networks is an intricate and multifaceted process that can yield impressive results if executed correctly. However, numerous challenges can arise during this journey, significantly impacting the performance and accuracy of the model. Common issues such as overfitting and underfitting, as well as difficulties in convergence, can hinder the training process. Understanding these challenges is crucial for anyone delving into neural networks, as they can make or break the success of a given project.
One major challenge in training neural networks is overfitting, which occurs when a model learns not only the underlying patterns in the training data but also its noise and outliers. This leads to a situation where the model performs exceptionally well on the training data but poorly on unseen data, failing to generalize effectively. Conversely, underfitting happens when a model is too simplistic to capture the underlying trend of the data, resulting in poor performance both on training and test datasets. Striking the right balance between these two extremes is critical to developing robust models.
To mitigate overfitting, one widely used method is regularization, which introduces additional constraints into the training process. Popular techniques include L1 and L2 regularization, which penalize the weights of the model, thereby discouraging complexity. Another effective approach is dropout, where a fraction of the neurons is randomly deactivated during training sessions. This prevents the network from becoming overly reliant on specific neurons, promoting more generalizable features.
Another method is data augmentation, which involves artificially increasing the size of the training dataset by making modifications to the existing data. This can include rotation, scaling, or translation of images in computer vision tasks, allowing the model to learn from a wider variety of inputs. Early stopping is also beneficial; it halts training when performance on a validation set begins to degrade, preventing overfitting.
Comparison of Optimization Algorithms
Choosing the right optimization algorithm is fundamental for effectively training neural networks. Various algorithms can influence the model’s convergence speed and overall performance. Below is a brief comparison of some of the most commonly used optimization algorithms:
- Stochastic Gradient Descent (SGD): This widely adopted technique updates weights incrementally after each training example, allowing for efficient training on large datasets. However, it may converge slowly and can oscillate if the learning rate is not tuned properly.
- Momentum: This method builds on SGD by incorporating a fraction of the previous update into the current update, helping to smooth out the updates and accelerate convergence, especially in ravines.
- Adam: Combining the benefits of both AdaGrad and RMSProp, Adam adjusts the learning rate based on both the first and second moments of the gradients. It generally converges quickly and adapts well to different datasets.
- AdaGrad: This algorithm adapts the learning rate based on the frequency of updates, allowing for larger steps in less frequent dimensions. However, it can lead to premature convergence as the learning rate diminishes over time.
- RMSProp: Similar to Adam, RMSProp modifies the learning rate based on the magnitude of recent gradients, allowing for better performance in non-stationary environments.
The choice of optimizer can significantly affect the training dynamics, making it important to experiment with different algorithms to find the most suitable one for a given neural network architecture and dataset. Each optimizer has its strengths and weaknesses, and understanding these can lead to more effective training strategies.
Real-World Applications of Neural Networks
Neural networks, a key component of artificial intelligence, have found extensive applications across various industries, enhancing processes and driving innovation. These technologies mimic the human brain’s functionality, allowing machines to learn from data and make decisions, which has led to transformative impacts in sectors like healthcare, finance, and autonomous vehicles.
In healthcare, neural networks are revolutionizing diagnostics and treatment plans. For instance, deep learning algorithms analyze medical images, such as X-rays and MRIs, to detect anomalies faster and with greater accuracy than human radiologists. An example is Google’s DeepMind, which has shown promising results in early detection of eye diseases. Such technologies not only improve patient outcomes but also reduce the workload on healthcare professionals, enabling more efficient care delivery.
Innovative Use Cases Across Industries
Innovative use of neural networks extends beyond healthcare to numerous fields, showcasing their versatility. In finance, these networks are employed for fraud detection, risk management, and algorithmic trading. Neural networks analyze transaction patterns, flagging suspicious activities in real-time. For example, companies like PayPal leverage these systems to monitor millions of transactions daily, significantly mitigating fraud risks.
The automotive industry is another sector where neural networks shine, particularly in the development of autonomous vehicles. Companies like Tesla and Waymo utilize deep learning techniques to process vast amounts of sensor data, enabling vehicles to navigate complex environments. This technology enhances road safety and promises to reshape urban mobility.
The impact of these innovations is profound. The efficiency gains in healthcare translate to better resource allocation and patient care, while financial institutions benefit from reduced losses due to fraud. In the automotive industry, autonomous vehicles are set to redefine transportation, potentially reducing traffic accidents and emissions.
As neural networks continue to evolve, several potential future applications are emerging. These include:
- Personalized education through adaptive learning systems that tailor content to individual learning styles and rates.
- Smart agriculture using neural networks for crop monitoring and yield prediction, optimizing food production.
- Enhanced cybersecurity measures utilizing neural networks to predict and mitigate threats before they occur.
- AI-driven customer service chatbots that understand and respond to customer inquiries with human-like accuracy.
- Predictive maintenance in manufacturing, where sensors analyze equipment performance to anticipate failures before they happen.
The continual advancement of neural networks hints at a future where their applications will further integrate into everyday life, fostering innovation and enhancing efficiency across various sectors.
The Future of Neural Networks and Emerging Trends
As we look toward the horizon of technology, neural networks continue to evolve in remarkable ways, promising to revolutionize various fields. The future of neural networks is not just about improved algorithms; it encompasses a broader view of their capabilities and their integration into society. Ongoing research is pushing the boundaries of what these networks can achieve, leading to advancements that are set to impact everything from healthcare to autonomous systems.
Research in neural networks is advancing rapidly, with significant strides being made in several areas. One area of interest is the development of more efficient architectures that reduce computational requirements while maintaining performance. Techniques such as neural architecture search (NAS) are being employed to automate the design of network structures, leading to discoveries of novel architectures that humans may not have conceived. Additionally, the integration of transformer models into a variety of applications, including natural language processing and image recognition, has set a precedent for the capabilities of neural networks. These transformers allow for processing data in parallel and handling longer sequences, which enhances the efficiency of training and inference.
Emerging Trends in Neural Network Design
The future landscape of neural networks is anticipated to be shaped by several key trends that emphasize flexibility, efficiency, and explainability. These trends are essential for ensuring that neural networks can be effectively deployed in real-world applications.
One notable trend is the rise of federated learning, which enables decentralized model training across multiple devices while maintaining data privacy. This approach is particularly relevant for industries like healthcare, where patient data confidentiality is paramount. Another critical trend is the move towards explainable AI (XAI), which aims to make neural networks more transparent and interpretable. Developing models that can explain their reasoning will help build trust with users and stakeholders, ensuring that decisions made by these systems can be understood and audited.
Additionally, there is an increasing focus on the sustainability of neural networks, as researchers seek to minimize the carbon footprint associated with training large models. Techniques such as quantization, pruning, and knowledge distillation are being explored to create more energy-efficient networks without compromising performance.
Ethical Considerations and Implications
As neural networks become more advanced, significant ethical considerations arise, particularly regarding their impact on society. The deployment of these technologies calls for a careful examination of issues such as bias, privacy, and accountability. For instance, if a neural network is trained on biased data, it can perpetuate and even exacerbate inequalities in decision-making processes, especially in critical areas like hiring or law enforcement.
Moreover, the use of neural networks in surveillance and data collection raises privacy concerns. The ability to analyze vast amounts of personal data can lead to invasive practices if not managed responsibly. Therefore, establishing robust ethical guidelines and regulations surrounding the use of neural networks is crucial to ensure that these technologies are harnessed for the greater good.
In summary, the future of neural networks is a blend of innovation and responsibility. As advancements continue to unfold, it is essential to balance technological progress with ethical considerations to ensure that neural networks contribute positively to society.
Summary
In conclusion, Neural Networks are at the forefront of technological innovation, offering unprecedented capabilities across multiple sectors. As we have seen, the understanding of their fundamentals, architecture, and training processes is crucial for leveraging their full potential. Moving forward, the ongoing advancements and emerging trends in this field promise to unlock even more possibilities, while also raising important ethical considerations that society must address. The journey of Neural Networks is just beginning, and their impact on our world will only grow more profound in the years to come.
Commonly Asked Questions
What are Neural Networks in simple terms?
Neural Networks are computational models inspired by the human brain, designed to recognize patterns and learn from data.
How do Neural Networks learn?
They learn by adjusting the weights of connections between neurons based on the data they process through a method called training.
What is the role of activation functions in Neural Networks?
Activation functions determine whether a neuron should be activated or not, introducing non-linearity into the model.
Why is training data important for Neural Networks?
Quality and quantity of training data directly affect the performance and accuracy of Neural Networks in making predictions.
What are some real-world applications of Neural Networks?
They are used in various fields including image recognition, natural language processing, and financial forecasting.
What challenges do Neural Networks face during training?
Common challenges include overfitting, underfitting, and the need for extensive computational resources.
What is deep learning and how is it related to Neural Networks?
Deep learning is a subset of machine learning that uses multi-layered Neural Networks to process data, allowing for more complex functions.
What are some trends shaping the future of Neural Networks?
Emerging trends include advancements in model architecture, increased computational power, and a focus on ethical AI practices.